

Come smettere di imporre Google agli utenti, senza rimpianti
Una guida pratica per passare da Google Analytics a qualcosa di meno invasivo, con tutti i dettagli tecnici che di solito mancano.


Installare Google Analytics su un sito significa fare una scelta per conto degli utenti senza chiedergli niente. Nessuno ci pensa davvero perché GA è lì da sempre, è gratuito, funziona. Ma fermarsi un momento a capire cosa succede esattamente, e poi decidere con più consapevolezza, ha senso.
Questa guida prova a spiegare com’è fatto il problema, quali alternative esistono, e come si fa concretamente il passaggio perdendo il meno possibile lungo la strada.
Cosa succede quando qualcuno visita un sito con GA
Ogni volta che un browser carica un sito con lo script di Google Analytics, manda una richiesta ai server di Google. In quella richiesta ci sono: l’URL che l’utente sta visitando, il referrer (da dove viene), il tipo di dispositivo, il browser, la risoluzione dello schermo, la lingua del sistema, e un identificativo persistente che permette a Google di riconoscere lo stesso utente su siti diversi nel tempo.
Questi dati non vengono usati solo per dare le statistiche nella dashboard. Vengono aggregati con tutto quello che Google già sa di quella persona dal resto del web: le ricerche su Google, i video su YouTube, le email su Gmail se le usa, i siti di tutto il resto del mondo che hanno GA installato. Il risultato è un profilo comportamentale che diventa sempre più preciso e che viene venduto agli inserzionisti sotto forma di targeting pubblicitario.
Il costo non è in denaro. Gli utenti pagano con i propri dati ogni volta che visitano il sito.
Lo si può leggere nei bilanci di Alphabet, scritto chiaro. La divisione che include Search, Maps e la rete pubblicitaria vale circa 270 miliardi di dollari all’anno. Quella cifra esiste perché miliardi di persone vengono osservate su miliardi di siti, e i loro comportamenti vengono trasformati in previsioni sui loro acquisti futuri. Shoshana Zuboff ci ha scritto un libro di 700 pagine chiamandolo “capitalismo della sorveglianza”: l’idea è che l’esperienza umana è diventata la materia prima di un’industria estrattiva, esattamente come il petrolio. Chi installa GA sul proprio sito è un fornitore non pagato di quella materia prima.
Un singolo sito, da solo, cambia poco nell’economia complessiva della sorveglianza digitale. Ma chi costruisce qualcosa per altri ha spesso una posizione su come gli utenti dovrebbero essere trattati, almeno in teoria. Vale la pena allineare gli strumenti a quella posizione.
Cosa serve davvero da uno strumento di analytics
Prima di guardare le alternative, è utile chiedersi cosa si stia effettivamente usando di GA. Nella maggior parte dei casi, la risposta è molto meno di quello che la piattaforma offre.
Le domande a cui si vuole rispondere sono probabilmente queste: quante persone visitano il sito? Da dove arrivano (motori di ricerca, social, direct, referral)? Quali pagine leggono di più? In che paesi e città si trovano? Con che browser e dispositivo navigano?
Queste cose non richiedono il tracciamento individuale. Non serve sapere che “questo specifico utente è tornato tre volte questa settimana, la prima via Google e le altre due via direct”. Servono aggregati: sessioni totali, sorgenti di traffico, pagine più popolari. Sono informazioni completamente diverse, e per raccoglierle non serve profilare nessuno.
L’unico caso in cui il tracciamento individuale diventa genuinamente utile è quando c’è un funnel di conversione complesso, un e-commerce, o campagne pubblicitarie da ottimizzare a livello di segmento. In quel caso GA o qualcosa di equivalente è necessario, e questa guida potrebbe non essere quella giusta. Per tutti gli altri, le alternative privacy-friendly danno tutto quello che conta.
Le alternative che funzionano
Plausible Analytics è probabilmente il punto di partenza più sensato per chi viene da GA. È open source, nato in Estonia nel 2019, disponibile sia come SaaS (9 euro al mese fino a 10.000 pageview, poi a scalare) che come versione self-hosted gratuita. Non usa cookie, non costruisce profili individuali, non cede dati a terze parti. I server sono in Europa. Per determinare sessioni uniche usa un hash giornaliero basato su IP e user-agent che viene scartato dopo 24 ore: non c’è niente di persistente da qualche parte.
Lo script pesa circa 1 kilobyte. GA4 pesa 45. Vale la pena tenerlo a mente per chi ha la performance tra le priorità.
Fathom Analytics è simile a Plausible nel modello ma con una storia leggermente diversa, fondata in Canada. Più cara (14 dollari al mese), ma con qualche feature in più sul fronte dei custom events. Il codice è closed source, però la privacy policy è verificabile e il modello di business è trasparente.
Umami è un’alternativa open source che si può self-hostare completamente gratuitamente. Ha una dashboard pulita, supporta eventi custom, ed è scritta in Next.js quindi è semplice da deployare su qualsiasi host che supporti Node. Con un server o un account su Railway o Render, Umami gira in dieci minuti.
Matomo è la soluzione più ricca di funzionalità tra le alternative open source. È praticamente un GA self-hosted: ha segmentazioni, funnel, heatmap, session recordings. È anche la più pesante da installare e mantenere. Ha senso quando si migra da GA con la necessità reale di funzionalità avanzate, altrimenti è un cannone per sparare a una mosca.
Come si fa il passaggio in pratica
Il passaggio da GA a Plausible (prendo Plausible come esempio perché è quello con cui ho più esperienza diretta, ma i principi valgono per tutte le alternative) si fa in tre fasi.
Prima: esportare da GA quello che si vuole conservare. Lo storico non è portabile su Plausible, i dati non sono compatibili. Quello che si può fare è esportare i report rilevanti da GA prima di spegnerlo, così si ha un riferimento per confrontare i numeri dei prossimi mesi. GA permette di esportare in CSV da qualsiasi vista.
Seconda: installare Plausible in parallelo per un periodo. Conviene non spegnere GA subito. Lasciare girare entrambi per due o quattro settimane permette di confrontare i numeri e capire le differenze. Plausible tende a riportare meno sessioni di GA per via di come esclude il traffico dei bot, ma i trend sono coerenti. Quando i dati sembrano affidabili, si spegne GA.
Terza: rimuovere lo snippet di GA dall’HTML e dai tag manager. Questo è il passaggio che molti dimenticano o rimandano. Chi usa Google Tag Manager deve ricordarsi di rimuovere o disabilitare il tag GA da lì: non basta toglierlo dall’HTML se GTM è ancora attivo e configurato per iniettarlo.
Il problema di Firefox (e come risolverlo)
C’è un dettaglio tecnico che vale la pena conoscere prima di iniziare, perché altrimenti ci si ritrova a guardare dati incompleti senza capire perché.
Firefox attiva di default la Enhanced Tracking Protection. Tra i domini che blocca per default c’è plausible.io, perché compare nelle liste dei tracker usate da Firefox (non perché Plausible faccia tracking invasivo, ma perché le liste sono conservative e bloccano tutto quello che assomiglia a un dominio di analytics). Risultato: circa il 20% degli utenti, quelli su Firefox con impostazioni di default, non viene tracciato.
La soluzione è il proxy: invece di far caricare lo script direttamente da plausible.io, lo si fa passare attraverso il proprio dominio. Il browser vede una richiesta al sito, non a un dominio nelle sue liste di blocco, e tutto funziona.
Su Netlify il modo più semplice è usare il file public/_redirects. Si aggiungono queste due righe prima del catch-all SPA:
/js/pa.js https://plausible.io/js/pa-TUOHASH.js 200
/api/event https://plausible.io/api/event 200
L’hash nell’URL dello script si trova nella dashboard di Plausible sotto Settings → Goals and custom events → Script snippet. È un hash specifico per il sito.
Nell’HTML, invece di caricare lo script da plausible.io, lo si carica da /js/pa.js:
<script async src="/js/pa.js"></script>
Poi bisogna dire allo script dove mandare gli eventi, perché di default li manda a plausible.io invece che al proxy locale. Si crea un file separato (non inline, per non incappare in problemi con la Content Security Policy) con questo contenuto:
window.plausible = window.plausible || function() {
(window.plausible.q = window.plausible.q || []).push(arguments)
};
window.plausible.init({ endpoint: '/api/event' });
E lo si include nell’HTML subito dopo lo script principale:
<script async src="/js/pa.js"></script>
<script src="/js/plausible-init.js"></script>
Due cose non documentate in modo ovvio che fanno perdere tempo:
Netlify: usa
_redirects, nonnetlify.toml. Le regole di redirect verso URL esterni devono stare inpublic/_redirects. Se si mettono innetlify.toml, Netlify le ignora silenziosamente quando_redirectsesiste. Non lo dice da nessuna parte in modo chiaro, lo si capisce solo testando con curl e vedendo che arriva HTML invece del contenuto del proxy.L’opzione si chiama
endpoint, nonapiHost. Se si scriveapiHost, le pageview vengono comunque tracciate ma gli eventi custom no, e non si capisce subito il perché.
Su Vercel il meccanismo è identico ma la sintassi va in vercel.json:
{
"rewrites": [
{ "source": "/js/pa.js", "destination": "https://plausible.io/js/pa-TUOHASH.js" },
{ "source": "/api/event", "destination": "https://plausible.io/api/event" }
]
}
Su Cloudflare Workers si può fare la stessa cosa con un worker che fa il proxy delle due route. Plausible ha una guida dettagliata nella loro documentazione.
La CSP, se presente
Se il sito ha una Content Security Policy configurata, ci sono alcune cose da verificare.
Con il proxy attivo, plausible.io non serve più nella script-src né nella connect-src. Si può rimuovere del tutto se c’era. Gli script vengono caricati dal proprio dominio, quindi 'self' è sufficiente.
L’unica accortezza è il file di init: deve essere un file esterno servito dal proprio dominio, non uno script inline. Se lo si mette inline (<script>window.plausible.init(...)</script>), la CSP lo blocca in assenza di 'unsafe-inline' nella script-src. Un file separato caricato via src non ha questo problema.
Cosa cambia nella dashboard
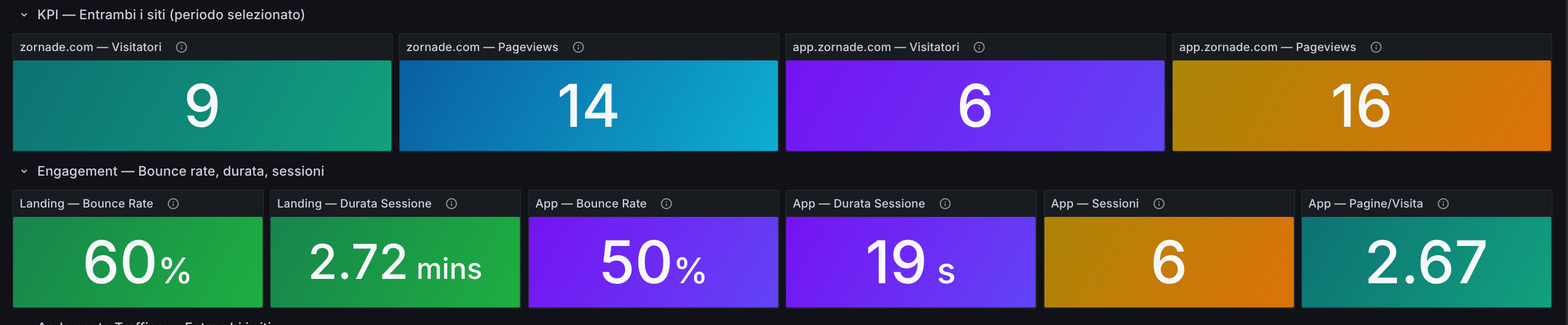
La prima cosa che si nota passando a Plausible è che i numeri sembrano più bassi di GA. GA ha una tendenza a gonfiare le sessioni includendo traffico di bot, sessioni di spam referral e ricariche di pagina spurie, e Plausible filtra in modo più aggressivo. Se si osservano i trend nel tempo invece dei numeri assoluti, le curve si comportano in modo coerente.
La seconda cosa è la semplicità. Plausible non ha una sidebar con quaranta voci. Ha una pagina con: visitatori unici, pageview, bounce rate, durata media, sorgenti di traffico, pagine più viste, dispositivi, paesi. Tutto in una schermata. Ci vuole letteralmente un decimo del tempo per trovare quello che serve rispetto alla navigazione di GA4.
Il banner cookie, in molti casi, non è più necessario. Plausible non usa cookie di tracciamento, quindi in molte interpretazioni del GDPR non rientra nell’obbligo del consenso per i cookie analitici. Prima di toglierlo del tutto è bene consultare la propria situazione specifica, perché le regole variano per giurisdizione e caso d’uso, ma nella maggior parte degli scenari si può farne a meno.
Vale la pena, in concreto
Il tempo per la migrazione dipende dalla complessità del sito. Per un sito statico o una SPA semplice, si contano un paio d’ore tra installazione, configurazione del proxy su Netlify o Vercel, e verifica che tutto funzioni. Se ci sono eventi custom configurati su GA da ricreare su Plausible, va aggiunto un po’ di tempo in più per rimappare la logica.
Il costo è 9 euro al mese per la versione SaaS fino a 10.000 pageview. Per siti più grandi, i prezzi scalano in modo lineare. La versione self-hosted è gratuita e il codice è su GitHub con licenza AGPL.
Quello che si ottiene in cambio, oltre alla questione etica: dati più puliti, una dashboard in cui si trovano le cose, nessun cookie banner forzato, GDPR più semplice da gestire, zero dipendenza da Google per un pezzo dell’infrastruttura.
Fare questo passaggio da soli cambia poco nell’economia complessiva della sorveglianza digitale. Ma per chi tiene a trattare bene le persone che usano quello che costruisce, è un passo che ha senso fare e che costa meno di quanto sembra.
Se l’articolo ti è stato utile, condividerlo con qualcuno che costruisce siti è il modo più diretto per supportare questo lavoro:
Link utili
Plausible Analytics — sito ufficiale, prezzi, demo
Plausible su GitHub — codice sorgente (licenza AGPL)
Guida al proxy per Netlify — documentazione ufficiale
Umami — analytics open source self-hosted
Fathom Analytics — alternativa closed source privacy-first
Matomo — analytics open source completo
Puoi iscriverti alla newsletter per capire come fare servizi web senza vendere l’anima a Larry Page: