
Uno strumento open source per mappe - con i dati italiani già dentro
Sto lavorando a un'alternativa libera a strumenti come Flourish e Datawrapper, pensata per chi lavora con confini, comuni e CAP italiani. Sarà software aperto sotto AGPL. Repo entro fine estate.

Nello scorso articolo ho parlato dell’ultima iterazione della strategia open source elaborata dalla Commissione Europea (la chiamano Open Internet Stack), dicendo in pratica che non smuove nulla e che resterà relegata a un addendum puramente cosmetico del Technological Sovereignty Package, approvato a inizio giugno. Ne parlavo anche perchè pubblico molte cose con licenze open (questo, questo, e tutti questi dati). Oggi vorrei parlare invece di un nuovo progetto (sempre open source) che sto sviluppando da inizio 2026 e che spero vedrà la luce entro fine estate.
Nel corso degli ultimi 12 mesi ho avuto modo di verificare che chi fa una mappa per una testata italiana ha, oggi, due alternative. La prima è abbonarsi a uno strumento proprietario (tipo Datawrapper o Flourish, che dal 2022 è dentro Canva) e imparare a usarlo. La seconda è commissionare la grafica a uno studio esterno. Mi spiazza pensare che per chi vuole fare elaborazioni geospaziali complesse esiste quello strumento magnifico che è QGIS, mentre chi ha bisogno semplicemente di pubblicare una webmap in velocità si trova invischiato in un groviglio di software proprietari e sistemi chiusi. Che schifo.
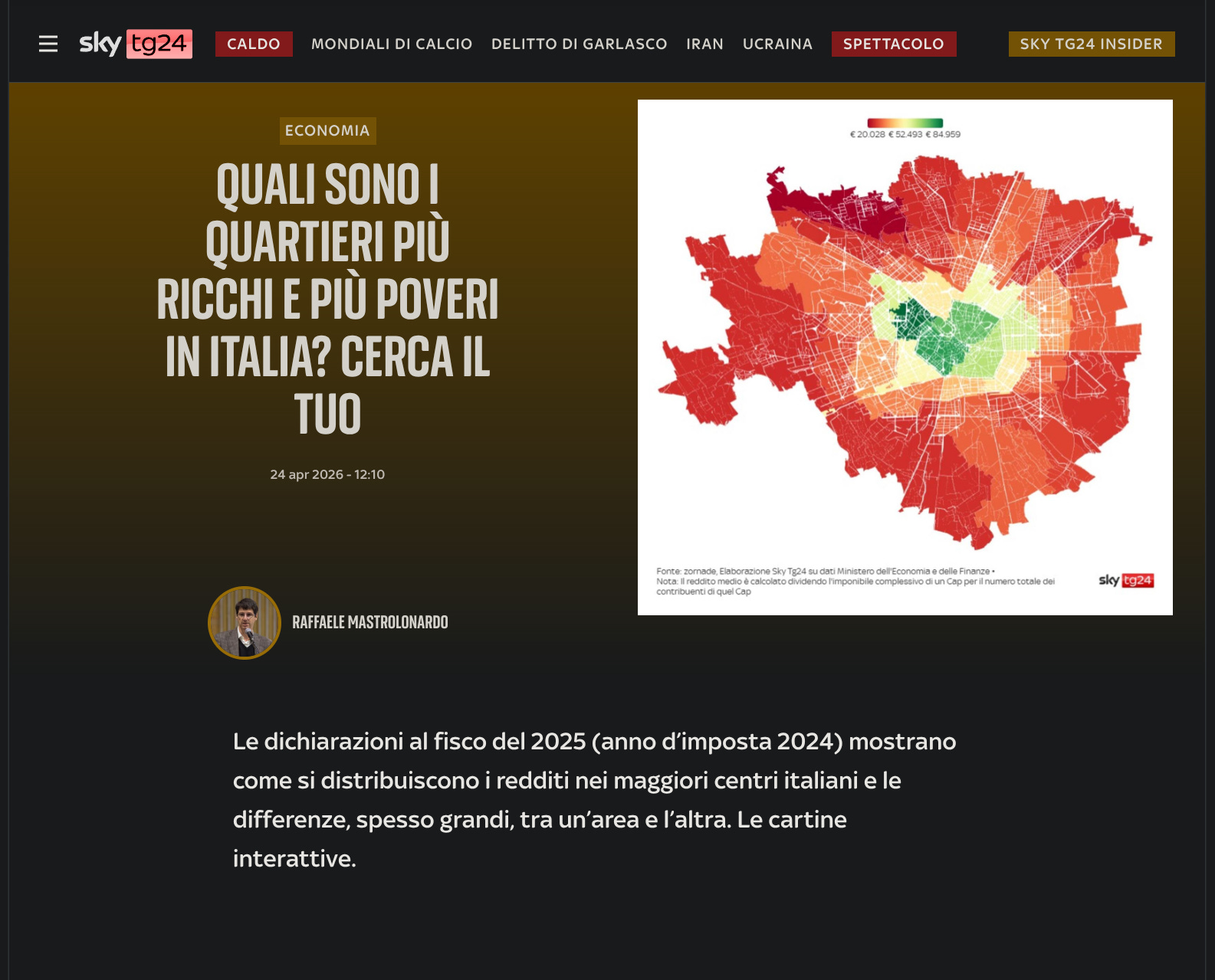
Da mesi con zornade produco mappe e visualizzazioni per alcune redazioni con cui collaboro, e ogni volta mi tocca fare il lavoro, sporco ma estremamente ripetitivo, dei join spaziali. A un certo punto la domanda è diventata ovvia: invece di rifare i join spaziali per la centesima volta, perché non costruire lo strumento che vorrei usare, con i geodati italiani già caricati dentro?
Quello strumento adesso esiste, si chiama Zornade Studio, e questo articolo è un aggiornamento pubblico dal suo cantiere.
Cosa fa
Studio è una webapp in cui carichi dei dati (CSV, Excel, GeoJSON), li abbini alla geografia italiana, scegli una visualizzazione (mappa, grafico, tabella, scrollytelling), applichi il tema della redazione (font, colori, logo) e pubblichi un embed da incollare nel sito.
Si carica un foglio “comune - valore” per ottenere una coropletica corretta in pochi secondi, perché il join su comune (o provincia, o regione, o CAP) lo fa lo strumento, non l’utente. Dietro ci sono i geodati che costruiamo come lavoro principale: i confini amministrativi ISTAT, le 9.228 zone CAP subcomunali (i CAP non sono poligoni ufficiali, ce li siamo ricostruiti, ma questa è un’altra storia che ho già raccontato), i prezzi immobiliari OMI semestrali dal 2015 al 2025, il rischio territoriale, il potenziale solare per edificio. È il motivo per cui una redazione dovrebbe scegliere questo e non Flourish: non l’interfaccia, ma il fatto che i dati italiani sono già pronti per la mappa.
Sopra ci ho agganciato i cataloghi aperti, in modo che il dato si possa cercare senza uscire dall’app: gli open data italiani (dati.gov.it, i portali di regioni e comuni), gli open data europei di data.europa.eu (un catalogo che a fine giugno 2026 conta circa 1.7 milioni di dataset federati), le statistiche Eurostat (più di 8’000 dataset) e le query a OpenStreetMap via Overpass per i punti di interesse (scuole, ospedali, porti, telecamere, eccetera). Si trova il dato, lo si carica, lo si mappa. Senza scaricare tre file, riproiettarli e pulirli a mano.
Perché software libero, e perché AGPL
Qui voglio essere esplicito, che la scelta di licenza non è un dettaglio legale da nascondere in fondo. Il repository di Studio sarà pubblicato sotto GNU AGPL v3: ovvero copyleft integrale. Vuol dire che chiunque faccia girare una versione modificata su un proprio server è tenuto a renderne disponibile il codice. È la stessa posizione che tengo sul resto di quello che faccio, ed è una posizione che cerco di mantenere in modo coerente: l’infrastruttura con cui si raccontano i dati pubblici dovrebbe essere ispezionabile, come i dati pubblici stessi.
C’è anche una ragione più immediata. Uno strumento editoriale chiuso è una preghiera sulla buona fede di chi lo distribuisce. Flourish era un prodotto indipendente, poi è stato comprato; Datawrapper è solido oggi, ma il prezzo del piano Custom (5.990 dolla l’anno per dieci utenti, mica cotiche) lo decide qualcun altro e lo può cambiare domani.
Quando lo strumento è libero, quella leva non ce l’ha nessuno sopra di te: puoi farlo girare per conto tuo, puoi correggerlo, puoi forcarlo se prende una direzione che non condividi.
Lo stack su cui è costruito riflette la stessa logica. Sono tutte librerie a licenza permissiva, scelte una per una controllando la licenza sul registro ufficiale: MapLibre GL JS (BSD) per le mappe, Observable Plot e Apache ECharts per i grafici, Scrollama per lo scrollytelling, i tile vettoriali in formato PMTiles serviti come file statici.
Cosa distingue Studio dai concorrenti
Intanto, lo ripeto, che è open source. Gli utenti potranno o usare la versione già pronta e servita da me, che costerà comunque meno di possere una VPS propria oppure, appunto, selfhostarlo aggratis. I dettagli li deciderò più avanti.
Sulla pura ricchezza di tipi di grafico, sull’animazione, sulla rifinitura dell’interfaccia, le differenze che contano per chi lavora sui dati italiani sono tre.
La prima l’ho detta: i geodati italiani con join automatico. È l’unica cosa che gli altri non possono replicare scaricando una libreria, perché non è codice ma il dataset che mantengo io.
La seconda è che l’embed è pensato per durare. Quello che si pubblica è uno snapshot statico su CDN, non una pagina che a ogni apertura chiama un’API a consumo che un domani può cambiare prezzo o spegnersi. Una mappa incorporata in un articolo del 2026 deve funzionare anche nel 2031, quando di quell’articolo non si ricorda più nessuno tranne chi lo cerca su Google (o, meglio, su DuckDuckGo o Brave).
La terza è il time slider sui dati che abbiamo già storicizzati. Una mappa dei prezzi OMI che scorre dal 2015 al 2025 con il tasto play è il tipo di cosa che, con i dati italiani sparsi su portali diversi, normalmente costa giorni di pulizia. Qui la serie storica è già dentro.
Sotto tutto questo c’è una scelta architetturale che si vede poco ma conta: ogni visualizzazione è un documento JSON dichiarativo, separato dal rendering. Lo stesso documento produce la versione interattiva e quella statica (per la stampa, per l’email, per chi ha JavaScript disattivato). È la parte noiosa e invisibile che rende lo strumento estendibile invece che uno scaldabagno.
Come lo sto costruendo
Per ora Studio non è pubblico per scelta. Lo sto sviluppando internamente, usandolo per produrre mappe vere insieme ad alcune redazioni e a un piccolo gruppo di data journalist a noi vicini. Ogni mappa che esce su una testata è un collaudo, e ogni feedback diretto vale oro.
L’idea è arrivare a maturità e pubblicare il repository entro la fine dell’estate. Non metto una data al giorno perché sappiamo tutto come vanno queste cose (e preferisco aprire qualcosa che funziona piuttosto che rispettare una scadenza che mi son dato da solo). Quando il codice sarà su GitHub sotto AGPL lo annuncerò qui, con i suoi limiti dichiarati in chiaro.
Extra: un progetto vicino che vale la pena seguire
Se questo tema vi interessa, c’è un gruppo di lavoro parallelo che consigliamo di tenere d’occhio: l’Associazione onData. onData fa advocacy per l’apertura dei dati pubblici come bene comune, ma soprattutto produce strumenti aperti e funzionali. La loro organizzazione su GitHub ha 139 repo pubbliche, e dentro ci sono cose che fanno felice chiunque si occupi di dati. Sono anche tra i promotori della campagna datiBeneComune (insieme ad ActionAid e Transparency International Italia), che spinge la pubblica amministrazione a pubblicare come open data cose che oggi restano chiuse.
Lo segnaliamo perché lavoriamo sullo stesso terreno da angoli diversi: loro spingono perché i dati siano aperti e maneggiabili, noi proviamo a renderli facili da mappare. Le due cose vanno a braccetto. Uno strumento per fare mappe italiane non serve a niente se i dati italiani restano dietro un PDF, e aprire i dati serve di più se poi qualcuno li sa raccontare.
Se fate parte di una redazione o siete datagiurnalist e volete provare Studio prima della pubblicazione (e dirci cosa non va), scriveteci. È esattamente il momento in cui un feedback cambia ancora le cose.